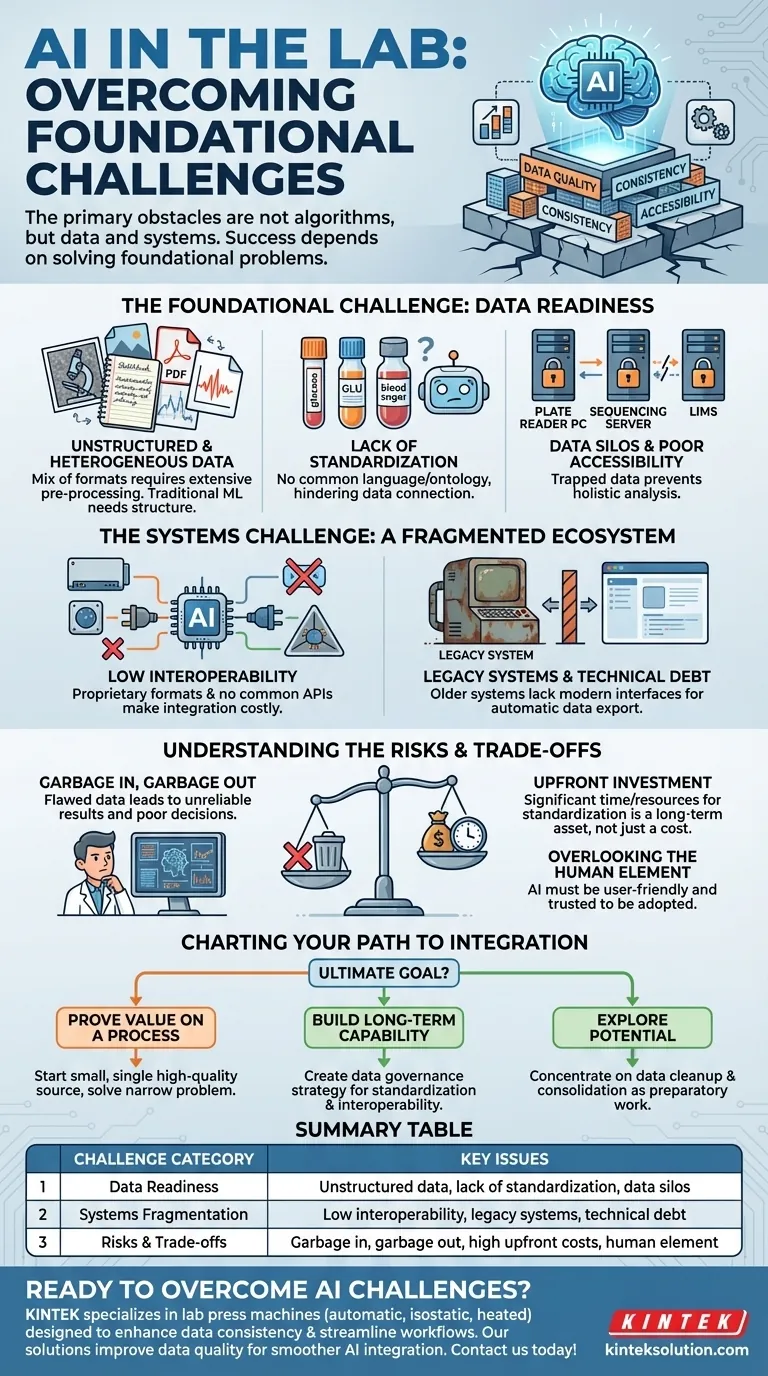
AI統合の主な障害は、アルゴリズム自体にあるのではなく、ラボの基礎となるデータとシステムにあります。最も重要な課題は、大量の非構造化データへの対処、データ標準化の広範な欠如、および異なるラボ機器とソフトウェアシステム間の低い相互運用性です。
ラボにおけるAIイニシアチブの成功は、最初のアルゴリズムが実行される前に決定されます。それは、データの品質、一貫性、およびアクセシビリティという基本的な問題を解決することにほぼ完全に依存しています。
基礎的な課題:データの準備状況
AIが洞察を提供する前に、クリーンで整理された、理解しやすいデータが必要です。残念ながら、一般的なラボ環境はしばしばその逆です。このデータの準備状況のギャップが最大のハードルです。
非構造化で異種データ
ほとんどのラボデータは、単純な表形式ではありません。顕微鏡からの画像、実験ノートのテキスト、機器の読み取り値のPDF、さまざまなデバイスからの生信号ファイルとして存在します。
AIモデル、特に従来の機械学習は、効果的に機能するために構造化されたデータを必要とします。このような形式の混在を広範な前処理なしに与えることは、失敗の元です。
標準化の欠如
データの命名、フォーマット、記録方法について、単一の強制的な標準がないことがよくあります。ある機器はサンプルを「glucose」と表示し、別の機器は「GLU」、そして手動の記録では「blood sugar」と呼ぶかもしれません。
共通の言語やオントロジーがなければ、AIは異なる実験やシステム間の関連データポイントを確実に結びつけることができません。この不整合は、全体像を把握するAIの能力を根本的に損ないます。
データのサイロ化とアクセシビリティの低さ
データはしばしば孤立したシステムに閉じ込められています。プレートリーダーからの出力は専用のPCに、シーケンスデータは別のサーバーに、サンプルメタデータはLIMS(ラボ情報管理システム)にロックされているかもしれません。
これらの「データのサイロ」は、AIが異なるソースからの情報にアクセスし、相関させることを妨げます。これは複雑なパターンを発見するために不可欠です。

システムの課題:断片化したエコシステム
ラボデータを生成するハードウェアとソフトウェアは、互いに連携するように設計されていることはめったにありません。この断片化は、AI統合プロジェクトに計り知れない技術的摩擦を生み出します。
低い相互運用性
異なる機器は、しばしば競合するベンダーから提供され、独自のソフトウェアとデータ形式を使用しており、互いに通信しません。データの抽出には、手動でのエクスポート、カスタムスクリプトが必要な場合や、不可能である場合もあります。
このような共通の通信プロトコル(APIなど)の欠如は、システムとAIプラットフォーム間の新しい接続がすべて、カスタムでコストのかかる統合プロジェクトになることを意味します。
レガシーシステムと技術的負債
多くのラボは、長年にわたって信頼されてきた古い機器やソフトウェアに依存しています。これらのレガシーシステムは、AIが要求するデータ中心の相互接続された世界のために設計されたものではありませんでした。
それらは、データを自動的にエクスポートするために必要な最新のインターフェースを欠いていることが多く、大きな障壁となります。それらを置き換えるのは費用がかかりますが、それらを回避する作業は複雑で脆弱です。
トレードオフとリスクの理解
これらの基本的な課題を無視してAIプロジェクトを推進することは、重大なリスクを伴い、失敗の最も一般的な原因となります。
「ゴミを入れればゴミが出る」のリスク
これはデータサイエンスの最も重要なルールです。矛盾した、乱雑な、または不正確なデータでトレーニングされたAIモデルは、信頼できない誤解を招く結果を生成します。
さらに悪いことに、欠陥のあるAI予測に基づいた不適切な科学的またはビジネス上の意思決定につながる、誤った信頼感を生み出す可能性があります。問題はモデルではなく、データにあるのです。
先行投資のコスト
データ標準化とシステム相互運用性に適切に対処するには、時間、リソース、および人員の面でかなりの先行投資が必要です。近道はありません。
しかし、この投資はAIのコストとしてではなく、長期的な資産として見なされるべきです。クリーンでアクセスしやすいデータインフラストラクチャは、単一のAIプロジェクトだけでなく、ラボのあらゆる側面に利益をもたらします。
人的要素の見落とし
AIツールは、使用されて初めて効果を発揮します。システムが操作しにくい、既存のワークフローに統合されない、または科学者が信頼できない結果を出す場合、それは放棄されるでしょう。
成功する統合には、エンドユーザーエクスペリエンスに焦点を当て、AIが科学者の作業を中断させるのではなく、補完するような明確で説明可能な結果を提供することを確実にすることが必要です。
AI統合への道のりを描く
AIを実装するための戦略は、最終的な目標によって決まるべきです。最初の適切なステップは、あなたの野心の規模によって異なります。
- 特定のプロセスで価値を証明することに重点を置いている場合:単一の高品質なデータソースから始め、狭く明確に定義された問題を解決することから始めましょう。
- 長期的なラボ全体のAI能力を構築することに重点を置いている場合:最初のプロジェクトは、標準化と相互運用性に正面から取り組むデータガバナンス戦略を策定することである必要があります。
- 単にAIの可能性を探ることに重点を置いている場合:データクリーンアップと統合に集中してください。これは、将来のAIの取り組みにとって最も価値があり、必要な準備作業だからです。
最終的に、ラボをAIのために準備するということは、クリーンで接続された、アクセス可能なデータの強固な基盤を構築することです。
要約表:
| 課題カテゴリ | 主な問題点 |
|---|---|
| データの準備状況 | 非構造化データ、標準化の欠如、データのサイロ化 |
| システムの断片化 | 低い相互運用性、レガシーシステム、技術的負債 |
| リスクとトレードオフ | ゴミを入れればゴミが出る、高い先行投資、人的要素 |
ラボでのAI統合の課題を克服する準備はできていますか? KINTEKは、自動ラボプレス、等静圧プレス、加熱ラボプレスなどのラボプレス機に特化しており、データの整合性を高め、ラボのワークフローを効率化するために設計されています。当社のソリューションは、データの品質とシステム間の相互運用性を向上させ、AI統合をよりスムーズかつ効果的にするのに役立ちます。今すぐお問い合わせください。お客様のラボのニーズをサポートし、イノベーションを推進する方法についてご紹介します!
ビジュアルガイド