AIのためにウェットラボのデータを準備するには、その生データ、多くの場合一貫性のない状態から、構造化された機械が読み取れる形式に変換する必要があります。これは単一のステップではなく、明確なルールを作成するためのデータガバナンスと、それに続くデータパイプラインによって自動的に生実験出力をクリーニング、正規化、構造化し、モデルトレーニングに適した一貫した形式に変換する体系的なプロセスです。
中心的な課題は、単にファイルを再フォーマットすることではありません。それは、実験条件、サンプル履歴、測定技術などの複雑な生物学的コンテキストを、重要な科学的意味を失うことなくAIモデルが学習できるような構造化された数値表現へと体系的に翻訳することです。

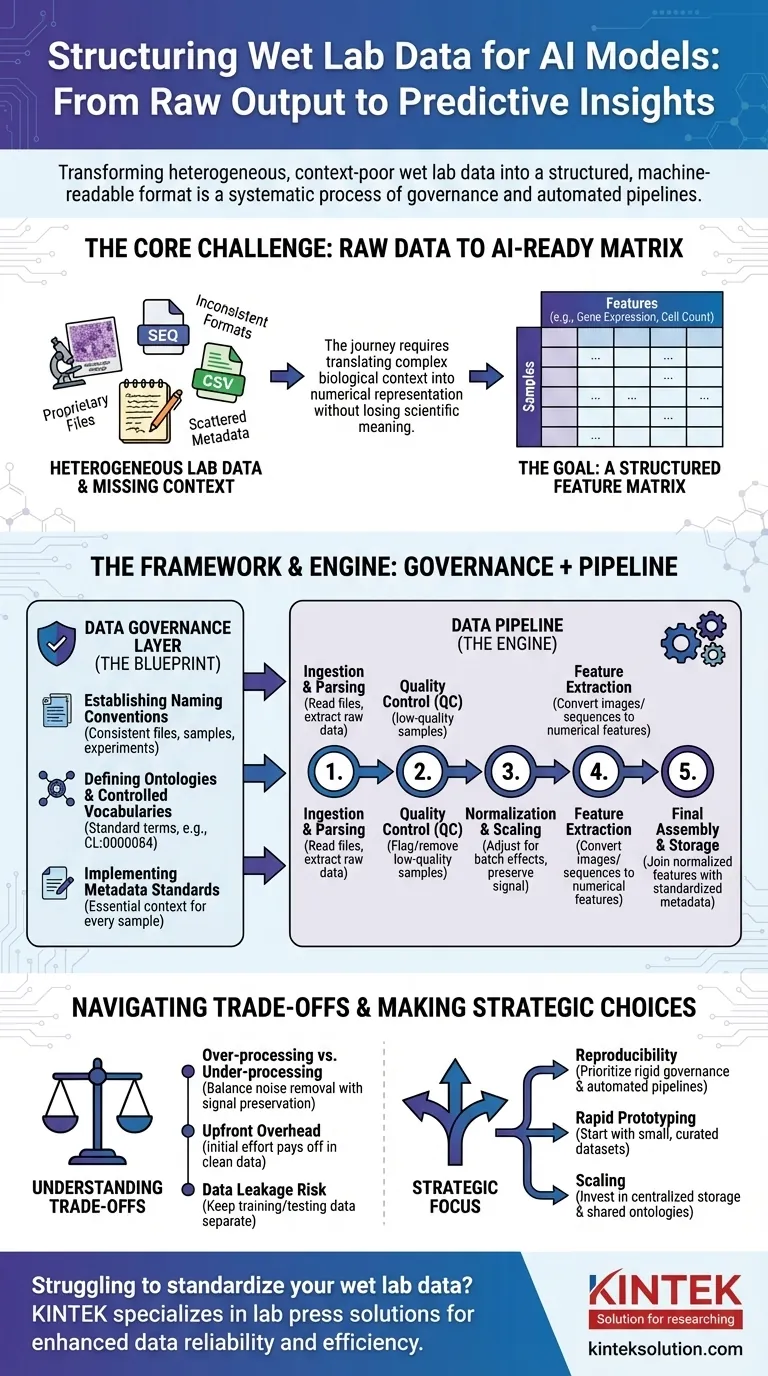
コアな問題:生データ出力からAI対応データへ
研究室のベンチから予測モデルに至る道のりは、データの問題に満ちています。科学機器からの生データ出力が、AIアルゴリズムで直接使用できる状態であることはほとんどありません。
ラボデータの異種性
ウェットラボのデータは、非常に多様な形式で提供されます。これには、シーケンサーや顕微鏡からの独自のファイルから、プレートリーダーからの単純なCSVまで、それぞれ独自の構造と特有の癖を持つものが含まれます。
しかし、AIモデルには統一された形式が必要です。
コンテキスト欠落の呪い
重要な情報、すなわちメタデータは、しばしば散在しています。それは科学者のノート、別のスプレッドシート、あるいは単に彼らの頭の中にあるかもしれません。このコンテキスト(例:どの薬剤が適用されたか、温度、使用された細胞株など)がなければ、数値データは意味をなしません。
目標:特徴量行列
結局のところ、ほとんどのAIモデルはデータを特徴量行列という形式で必要とします。これは、行が個々のサンプル(例:患者、細胞培養ウェル)を表し、列が特徴量(例:遺伝子発現レベル、細胞形態測定値、タンパク質濃度)を表す単純な表です。
標準化のフレームワーク:データガバナンス層
自動化されたパイプラインを構築する前に、ルールを確立しなければなりません。これがデータガバナンスであり、すべての実験とチーム間の一貫性を保証するための設計図です。これは最も重要でありながら、見過ごされがちなステップです。
命名規則の確立
単純だが強力なルールは、ファイル、サンプル、実験に対して一貫した命名スキームを強制することです。これにより、データをその起源から最終分析までプログラム的にリンクし、追跡することが可能になります。
オントロジーと制御語彙の定義
オントロジーは、生物学的実体を記述するための標準化された用語セットを提供します。例えば、「T-cell」、「T lymphocyte」、「Tcell」を許可する代わりに、制御語彙は細胞オントロジーのCL:0000084のような単一の用語を強制します。
これにより曖昧さがなくなり、異なる実験からのデータが真に比較可能であることが保証されます。
メタデータ標準の実装
すべての単一サンプルについて、必ずキャプチャしなければならない最小限のメタデータを定義する必要があります。これには、サンプルの出所、実験条件、機器の設定、日付などが含まれることがよくあります。このルールは、データポイントがいかなるコンテキストからも切り離された孤児になることを防ぎます。
変換のエンジン:データパイプラインの構築
ガバナンスルールが確立されたら、データパイプラインを構築できます。これは、生データを最終的なAI対応の特徴量行列に変換する一連の自動化されたソフトウェアステップです。
ステップ1:データ取り込みと解析(パーシング)
パイプラインの最初の仕事は、生データファイルを見つけて読み取ることです。このステップには、各機器の出力形式に対応する特定のパーサーを作成し、主要な測定値と関連するメタデータを抽出することが含まれます。
ステップ2:品質管理(QC)
すべてのデータが良質なデータであるわけではありません。パイプラインは、イメージング実験における低い細胞数やシーケンサーからの低いリード品質など、事前に定義されたメトリクスに基づいて低品質のサンプルを自動的にフラグ付けまたは削除する必要があります。
ステップ3:正規化とスケーリング
異なるバッチやプレートからの測定値には、技術的なばらつきがあることがよくあります。正規化は、生物学的シグナルを維持しつつ技術的なノイズを除去し、実験間で測定値を比較可能にするようにデータを調整する重要なステップです。
ステップ4:特徴量抽出
生データは特徴量形式になっていないことがよくあります。例えば、画像は細胞のサイズ、形状、強度などの数値的特徴量を抽出するために処理される必要があります。DNA配列はk-mer頻度ベクトルに変換されるかもしれません。このステップは、複雑なデータをAIが使用できる数値に変換します。
ステップ5:最終的な組み立てと保存
最後に、パイプラインは正規化された特徴量と標準化されたメタデータを結合します。これにより、最終的でクリーンな特徴量行列が作成され、モデルトレーニングのために安定した、問い合わせ可能な形式(Parquetやデータベースなど)で保存されます。
トレードオフの理解
データの構造化は中立的なプロセスではありません。あなたが下すすべての選択が、最終的なモデルのパフォーマンスと解釈に影響を与える可能性があります。
過剰処理 vs. 不足処理
積極的な正規化やフィルタリングは、微妙だが重要な生物学的シグナルを削除してしまうことがあります。逆に、技術的なノイズを除去できないと、モデルが生物学ではなく実験的アーティファクトから学習することが保証されます。これは絶え間ないバランスです。
標準化による初期オーバーヘッド
データガバナンスの実装には、多大な初期労力とチーム全体の合意が必要です。最初は研究を遅らせるように感じられるかもしれませんが、後で何ヶ月にもわたるクリーンアップ作業を防ぐことで、莫大な利益をもたらします。
データリークの危険性
パイプラインの重要な機能は、トレーニングデータとテストデータを分離しておくことです。テストセットの情報(例:その全体的な分布)がトレーニングセットの正規化に使用されると、モデルのパフォーマンスは人為的に誇張され、現実世界では失敗します。
目標に合わせた適切な選択
データ構造化へのアプローチは、最終的な目的に導かれるべきです。
- 再現性が主な焦点の場合:初日から厳格なデータガバナンスとバージョン管理された完全に自動化されたパイプラインを優先します。
- 迅速なプロトタイピングが主な焦点の場合:AIアプローチを検証するために、小規模で手動でキュレーションされたデータセットから始めてから、本格的なパイプラインに投資します。
- 大規模組織全体でのスケーリングが主な焦点の場合:データサイロを防ぐために、集中化されたデータストレージ、共有オントロジー、および共通のパイプラインコンポーネントに重点的に投資します。
結局のところ、ウェットラボの実験と同じ厳密さをもってデータを取り扱うことが、成功した信頼できる生物学的AIを構築するための基盤となります。
要約表:
| ステップ | 主要なアクション | 目的 |
|---|---|---|
| データガバナンス | 命名規則、オントロジー、メタデータ標準の確立 | 実験間の一貫性と比較可能性の確保 |
| データパイプライン | 取り込み、解析、QC、正規化、特徴量抽出、組み立て | 生データをAI対応の特徴量行列に自動変換する |
| トレードオフ | 過剰処理と不足処理のバランスを取る、オーバーヘッドの管理 | モデルパフォーマンスの最適化とデータリークの回避 |
AIのためにウェットラボの標準化に苦労していませんか? KINTEKは、自動ラボプレス機、静水圧プレス機、加熱ラボプレス機を含むラボプレス機を専門としており、データの信頼性と実験効率の向上を支援するために研究所にサービスを提供しています。一貫した結果を達成するために、今すぐお問い合わせいただき、お客様のニーズについてご相談の上、当社のソリューションがAI駆動型研究をどのようにサポートできるかをご確認ください!
ビジュアルガイド